数据类型¶
在阅读本节之前,请确保你对 pymatgen.core.Structure 已经有了一定的了解并下载测试数据 Structure 测试样本和背景 。
定义¶
我们将特征的分为以下几种并定义名称:
原子/元素特征
原子/元素自身属性。
键特征
原子间键的属性。
状态(化合物整体)特征
结构整体属性,包含所有体现整体结构的属性。
晶体结构特征(Graph特征)
原子/元素特征, 键特征, 状态特征的集合。
备注
与1、2不同,2,4不能直接用于 sklearn , 但适用于 torch 。
应用¶
所有的特征产生工具,使用 convert 方法处理单一数据。fit_transform 方法批量处理数据列表。
1. 原子/元素特征¶
示例1:
示例2:
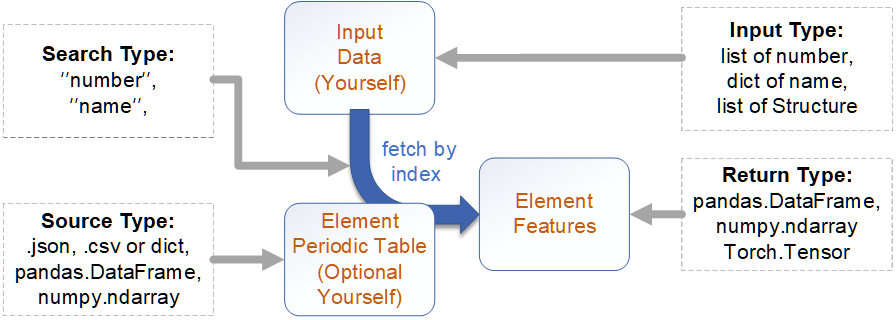
原子/元素特征可以通过调取元素周期表数据获取输入为两类数据。(至少一类)
- 你的输入单个数据。类型可以是元素序号列表或元素名的字典。
(我们有内置了转换函数转换
Structure,来直接得到化合物中的所有原子信息)。
- 元素周期表数据(可选)。
我们内置了一些元素周期表(“element_table.csv”, “ie.json”, “oe.csv”),若需要自定义元素周期表。你可以提供 (
.json,.csv) 文件或python数据类型(dict,pandas.DataFrame,numpy.ndarray).(
.json,dict) 用于AtomJsonMap,(
.csv,pandas.DataFrame,numpy.ndarray) byAtomTableMap.并且我们提供了一个特殊的
AtomPymatgenPropMap来调用pymatgen.core.periodic_table.json的数据。
示例:
Input atom list
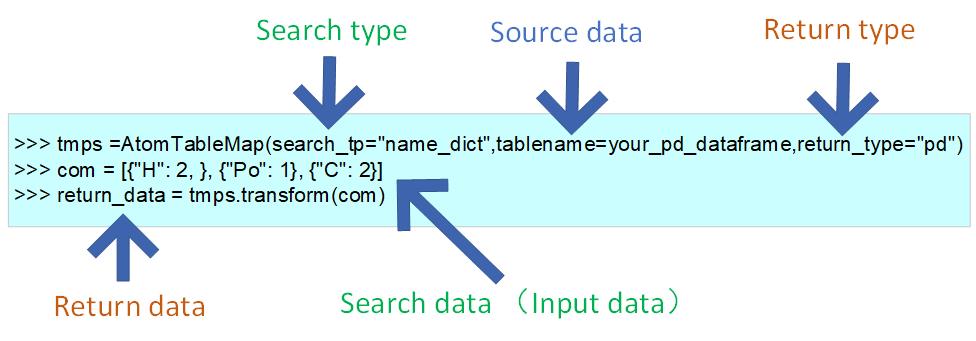
>>> from featurebox.featurizers.atom.mapper import AtomTableMap
>>> tmps = AtomTableMap(search_tp="number")
>>> single_sample = [1,1,1,76,76]
>>> multi_sample = [[1,1,1,76,76],[3,3,4,4]]
>>> a = tmps.convert(single_sample)
>>> b = tmps.transform(multi_sample)
Input element dict
>>> from featurebox.featurizers.atom.mapper import AtomJsonMap
>>> tmps = AtomJsonMap(search_tp="name",return_type="np")
>>> single_sample = [{"H": 2}, {"Po": 1}]
>>> single_sample2 = {"H": 2, "Po": 1}
>>> multi_sample = [[{"H": 2}, {"Po": 1}], [{"He": 3}, {"P": 4}]] # or
>>> multi_sample2 = [{"H": 2, "Po": 1}, {"He": 3, "P": 4}]
>>> a = tmps.convert(single_sample)
>>> a = tmps.convert(single_sample2)
>>> b = tmps.transform(multi_sample)
>>> b = tmps.transform(multi_sample2)
Input structure type
>>> from featurebox.featurizers.atom.mapper import AtomJsonMap
>>> tmps = AtomJsonMap(search_tp="name",return_type="np")
>>> a = tmps.convert(structurei)
>>> b = tmps.transform(structure_list)
- 更多参考:
示例:Pymatgen数据
2. 键特征¶
对于键合特征,需要使用结构数据提取信息。常见的结构数据包括 Pymatgen 的 Structure , ase 的 Atoms 等等。 Structure 与 Atoms 可以用 pymatgen.io.ase.AseAtomsAdaptor 相互转换。
3. 状态(化合物整体)特征¶
两种方式获取状态(化合物整体)特征
1. 从结构数据中提取信息。
示例:
>>> from pymatgen.core.structure import Structure
>>> structurei = Structure.from_file(r"your_path/featurebox/data/temp_test_structure/W2C.cif")
>>> from featurebox.featurizers.state.state_mapper import StructurePymatgenPropMap
>>> tmps = StructurePymatgenPropMap(prop_name = ["density", "volume", "ntypesp"])
>>> a = tmps.convert(structurei)
>>> b = tmps.transform([structurei]*10)
其中 prop_name 是 pymatgen 中的内置的一些属性名,这些属性名称可能不适用于所有化合物,数据不能保证是一个数字,有缺失,甚至错误:
prop_name = ["atomic_radius","atomic_mass","number","max_oxidation_state","min_oxidation_state",
"row","group","atomic_radius_calculated","mendeleev_no","critical_temperature","density_of_solid",
"average_ionic_radius","average_cationic_radius","average_anionic_radius",]
3.2 根据成分比例对原子特征的组合或数学运算。
这是获取状态特征的一种关键方法! 可以使用直接转换或者分步转换。
直接获取状态特性。
>>> from pymatgen.core.structure import Structure
>>> from featurebox.featurizers.state.statistics import WeightedAverage
>>> structurei =Structure.from_file(r"your_path/featurebox/data/W2C.cif")
>>> from featurebox.featurizers.atom.mapper import AtomTableMap
>>> data_map = AtomTableMap(search_tp="name", n_jobs=1)
>>> wa = WeightedAverage(data_map, n_jobs=1,return_type="df")
>>> x3 = [{"H": 2, "Pd": 1},{"He":1,"Al":4}]
>>> wa.fit_transform(x3)
>>> x4 = [structurei]*5
>>> wa.fit_transform(x4)
更多的组合操作,如 WeightedSum, GeometricMean, HarmonicMean, WeightedVariance 参考: featurebox.featurizers.state.statistics. 参考: Pymatgen数据.
分步获取状态特性(只针对具有相同原子种类数的组合)。
首先获取独立元素特性。
>>> from featurebox.featurizers.atom.mapper import AtomJsonMap
>>> from featurebox.featurizers.state.union import UnionFeature
>>> from featurebox.featurizers.state.statistics import DepartElementFeature
>>> data_map = AtomJsonMap(search_tp="name",embedding_dict="ele_megnet.json", n_jobs=1) # keep this n_jobs=1 and return_type="np"
>>> wa = DepartElementFeature(data_map,n_composition=2, n_jobs=1, return_type="pd")
>>> comp = [{"H": 2, "Pd": 1},{"He":1, "Al":4}]
>>> wa.set_feature_labels(["fea_{}".format(_) for _ in range(16)]) # 16 this the feature number of built-in "ele_megnet.json"
>>> couple_data = wa.fit_transform(comp)
首先获取独立元素特性。
>>> # couple_data is the pd.Dataframe table.
>>> # comp is the atomic ratio of composition.
>>> uf = UnionFeature(comp,couple_data,couple=2,stats=("mean","maximum"))
>>> state_data = uf.fit_transform()
备注
这里的 UnionFeature 可以用于您自己的元素表数据 (强烈建议)!
- 此外:
可以对状态特征进行多项式扩展,实现升维。
>>> import numpy as np
>>> from featurebox.featurizers.state.union import PolyFeature
>>> state_features = np.array([[0,1,2,3,4,5],[0.422068,0.360958,0.201433,-0.459164,-0.064783,-0.250939]]).T
>>> state_features = pd.DataFrame(state_features,columns=["f1","f2"],index= ["x0","x1","x2","x3","x4","x5"])
>>> pf = PolyFeature(degree=[1,2])
>>> pf.fit_transform(state_features)